

What are the benefits of Deep Learning for mobile apps?
Some years back, Artificial Intelligence consisted of a computer chess game which could compete against chess masters, beat them and show how robots...
4 min read


Let us begin with the truth about deep learning, artificial intelligence and machine learning. If you didn’t try to understand the concept of these three fast-growing technology then it is possible that in the next three years you will be living in the dinosaur era. In simple words, these technologies are going to take over the world at a fast speed so you need to learn them as soon as possible to be abreast with advancement.
In the Deep learning process, a scientist can actually design their own visions of neural networks. It could be run off while scaling out the training process of a company that will work along auto location. In simple words, you just have to pay for the resources that are utilized in the training. This is all due to the advancement in the technologies of Artificial intelligence that is going on for over a decade now. It has fueled up the volume of data and unprecedented advancement of deep learning.
There are mainly three trends that have given rise to Deep Learning:
Deep Learning process is widely known as neural network training which is computationally intensive and complex. In this system, the perfect combination of computing, drivers, software, network, memory and storage resources are utilized with high tuning. Additionally, if the full potential of Deep Learning must be realized then it must be accessible for the data scientists and developers. This will help them to complete their task efficiently such as neural network model training with the help of automation along datasets (especially large), refinement and concentration of data and cutting-edge model creation.
They are the main building blocks of technology that are widely used in the process of Deep Learning. It is a simple processing unit that can store knowledge easily and also to use the same data while making out predictions. In the neural network, the brain will predict network that in return acquire data from the environment with the help of the learning process. Then, synaptic weights are used for the connection strength that easily stores the information. They, synaptic weights, are modified in the learning process to make sure that goals are achieved.
It is usually compared with the human brain as explained by Karl Lashley, the neuropsychologist, in 1950. In the comparison, the main points taken are their non-linear operations that work on information processing with computation work such as perception and pattern recognition. In turns, these networks are extremely popular in the areas of recognition of audio, speech and image where inherently nonlinear signals are used.
The perceptron is the simplest layer of weights that help in the connection of outputs and inputs. This is the main reason that this system is considered as a feed-forward network where the data only moves in a single direction and cannot be reversed. It requires synaptic weights, summing junction, input signals,and activation signal to come up with a relevant output.
SLP can easily be conceptualized into grounding and clarification into the advanced mode of a multilayer perceptron. There is a total of m weights in SLP that represents the total set of synapses which are connected together with a link between multiple layer and single layer. This helps in the explanation of the character of each feature, xj.
uk = Σ(j = i to m) wkj * xj|
In such condition, bk bias will act as a transformation of affine to the output of the uk, adder functions that gives the total of the induced local field, vk.
vk = uk + bk
Now, this is a feed-forward type of network that has a total sequence of layers on which the work is done and that are connected to each other. In this, there is an extra layer that is hidden apart from input and output. Each and every layer will consist of different neurons that are connected to each other with the help of weight links. In the input layer, the neurons represent the total dataset or their attributes while in the output layer, they will be the dataset given in a class. Hidden layer is only introduced to make the task much simpler.
This technique of Deep Learning is implemented in Watson Studio by IBM earlier this year. There isa number of different features that are showcased in deep learning such as lowering the barrier so that all users can make an entry. The model in Watson Studio is so much enhanced with cloud-native along with an environment that supports end-to-end implementation for developers, data scientist, SMEs and business analysts to build up and train a model of AI. This can be done in semi-structured, structured and unstructured data along with the maintenance of an organization’s rules and policies.This has helped the system a lot for making it accessible and easy to scale. In addition to this, the automation process will also help in the reduction of complexity.
You need to understand that Deep Learning process is full of mathematical terms and calculations that can help in several ways. There is no need to worry about mathematical function since they are simply about integral and algebra. Apart from the above-mentioned points, you can also understand the robust model for deep learning that will include cost function, back propagation algorithm and gradient descent that are used to extensively for the model work. All you need to do is gain expertise and you are good to go.

Some years back, Artificial Intelligence consisted of a computer chess game which could compete against chess masters, beat them and show how robots...

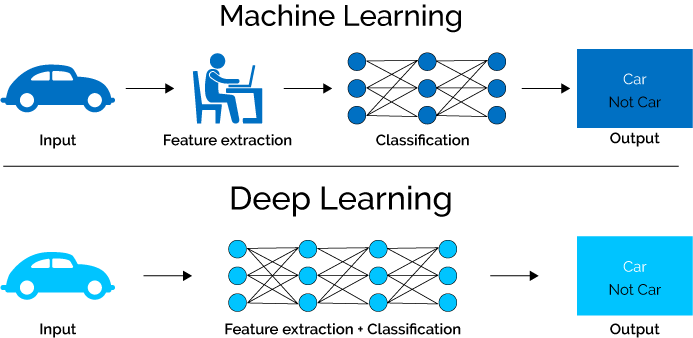
Deep Learning is regarded as a sub-branch of machine learning and is inspired by the function and structure of the brain called artificial neural...
Deep learning is a category of machine learning that creates algorithms known as artificial neural systems which operate by forming the function and...